Northwestern University и Университет Иллинойса запустили проект MONK.
MONK состоит из базы данных и программ, обнаруживающих повторяющиеся паттерны в текстах.
Программа отслеживает связки между отдельными словами и предложениями, частями речи и лексемами. Она также учитывает разнообразие диалектов.
Т.о. программа классификацирует тексты и вычислеяет вероятности появления лексем (например, по частоте появления слова в нескольких текстах вычислить вероятность появления текста в следующем).
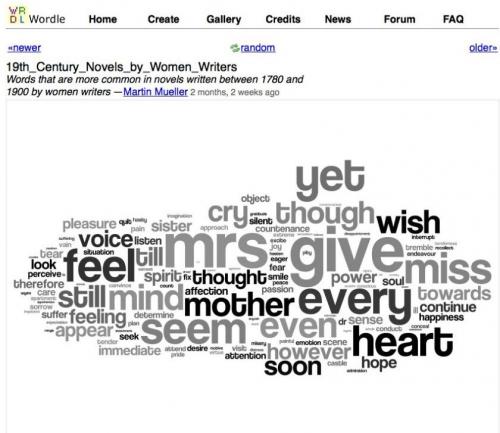
С помощью этого инструмента можно получить своеобразную ДНК текста и понять, вокруг каких смыслов строится текст, кто в нём присутствует и какие действия и характеристики наиболее типичны.
ок. Суть программы «один» — обработка статического изображения с применением специального фильтра, на выходе имеем обработанную картинку. Суть программы «два»…